System Design Interview was written by Alex Xu initially as a guide to the System Design Interview and later as more of a survey of the essential concepts and patterns that one might use in high level software architecture design.
The book uses popular patters for scaling reliable, distributed computing applications. It doesn't go into the details of particular cloud platforms of technology frameworks, trying instead to remain platform agnostic.
This book contains good advice for how one might approach a System Design interview. Its a good collection of practical patterns that apply to common distributed computing problems. Though some of the examples are more theoretical than most people are likely to encounter in their daily work, I've found the book to offer useful insights into some of the basic inner workings of many distributed applications. The book is also well written. Unlike some technical books, the book is written for accessibility and is paced well.
In this post, my goal is to summarize some of the important concepts discussed in the book. These summaries won't explain the concepts in detail so, if you want to learn more I highly recommend picking up a copy of the book.
Introductory Concepts
- Vertical vs Horizontal Scaling
- Load Balancer
- Sticky Sessions
- Database Replication
- Multi-Master Replication
- Circular Replication
- Caching Strategies
- Content Delivery Network (CDN)
- Stateless vs Stateful Applications
- Message Queues
- Host Level Metrics (CPU, Memory, Disk I/O)
- Sharding (Horizontal Database Scaling)
- Resharding Data
- Celebrity Problem
- Join & De-normalization
- Active-Active for Multi-Regional Resiliency
Estimation
Concepts
- Power of 2: data volume units and how to calculate
- Memory is fast, disk is slow (so avoid disk seeks if possible)
- Simple compression algorithms are fast (so compress before sending if possible)
Framework for System Design Interview
- Understand the Problem and Establish a Design Scope
- Propose a High-Level Design and Get Buy-in
- Design Deep Dive
- Wrap up
Tips for Interviews
- Write down your assumptions
- Label your units
Design a Rate Limiter
After narrowing scope we have a few issues to address
- Evaluate current technology stack
- Identify the Rate Limiting Algorithm
- High-Level Architecture
Popular Algorithms
- Token Bucket
- Leaking Bucket
- Fixed Window Counter
- Sliding Window Log
- Sliding Window Counter
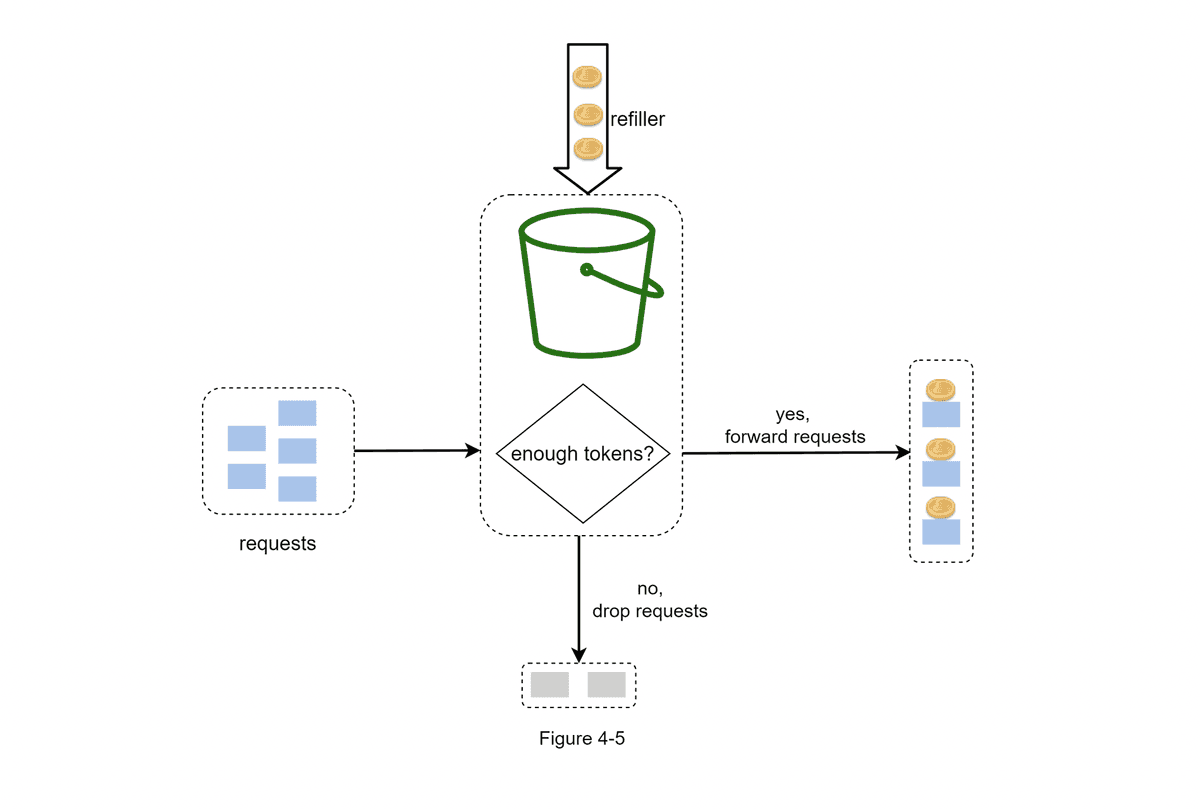
In this diagram, Alex Xu illustrates how token consumption, refill, and rate limiting logic works. In this example, the token bucket size is 4, and the refill rate is 2 per minute.
Architecture Design Considerations
- Where do we store counters? "In-memory cache is chosen because it is fast and supports time-based expiration strategy. For example Redis is a popular option to implement rate limiting."
- Where to add Rate Limiting Algorithm? The ideal location is the API Gateway which may also handles Authentication & Authorization. Keeping the rate limiter function here is helpful because it also saves on networking.
- How does a client know whether it is being throttled? "The answer lies in HTTP response headers. [...] When a user has sent too many requests, a 429 too many requests error and
X-Ratelimit-Retry-Afterheader are returned to the client". - Race Condition in Distributed Environment: consider Lua script and Sorted Sets data structure in Redis
- Synchronization in Distributed Environment: centralized data stores like Redis can help
- Performance Optimization? Place rate limiters close to the other system components and ideally the user (e.g. edge location).
- Monitoring? Gather analytics to ensure the Rate Limiter algorithm and rules are effective.
Design Consistent Hashing
A problem occurs when the pool of servers is scaled up or down. As a result nearly every record needs to be rehashed to assign a new server in the pool. In a scenario where this happens often, the re-hashing process causes cache clients to connect to the wrong servers and a storm of cache misses.
DEFINITION: Consistent Hashing is a special kind of hashing such that when a hash table is re-sized and consistent hashing is used only k/n keys need to be remapped (on average), where k is the number of keys and n is the number of slots.
Issues
- Server Lookup
- Add/Remove Server
- Non-uniform Key Distribution
- Hotspot Key Problem
Concepts
- Hash Space
- Hash Ring
- Hash Server
- Hash Key
- Virtual Nodes: as the number of virtual nodes increases, the distribution of keys becomes more balanced.
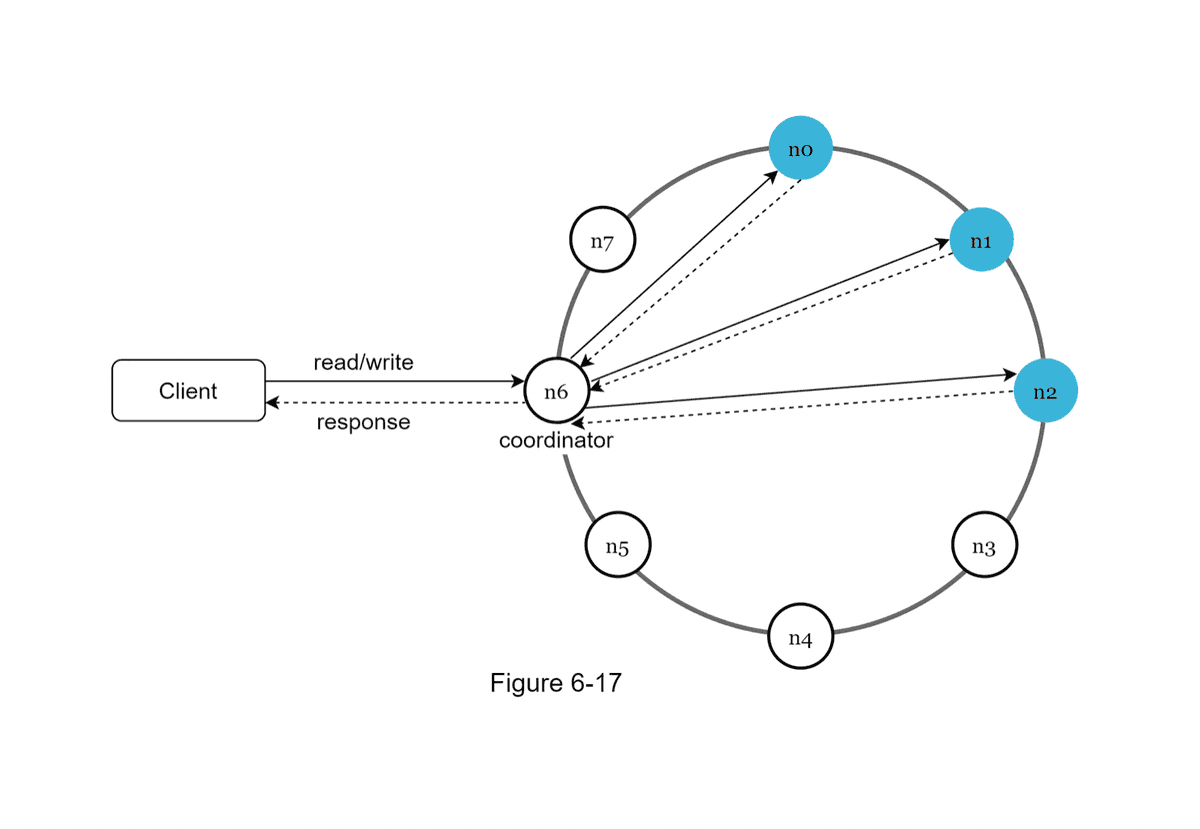
Design a Key Value Store
A key value store is also known as a non-relational database. Each unique identifier is stored as a key with its associated value. Developing a key-value store on a single server is easy as storing key-value pairs in a hash table which keeps everything in memory.
Issues Memory limitations pose our first issue. We could use compression and/or move infrequently accessed data to disk storage, but memory remains finite.
In addition, relying on a single server means our Key-Value Store would be unreliable.
We explore distributed solutions in order to achieve scalability, fault tolerance, and accessibility.
Concepts
- CAP Theorem (choice consistency or availability)
- Consistent Hashing: nodes are distributed on a ring using consistent hashing
- Data Replication: data is replicated at multiple nodes
- data must be replicated asynchronously over N servers
- for better reliability, replicas are placed in distinct data centers
- data centers are connected through high speed networks
- Consistency
- Data is synchronized across replicas
- Quorum consensus guarantees Consistency for both read and write operations
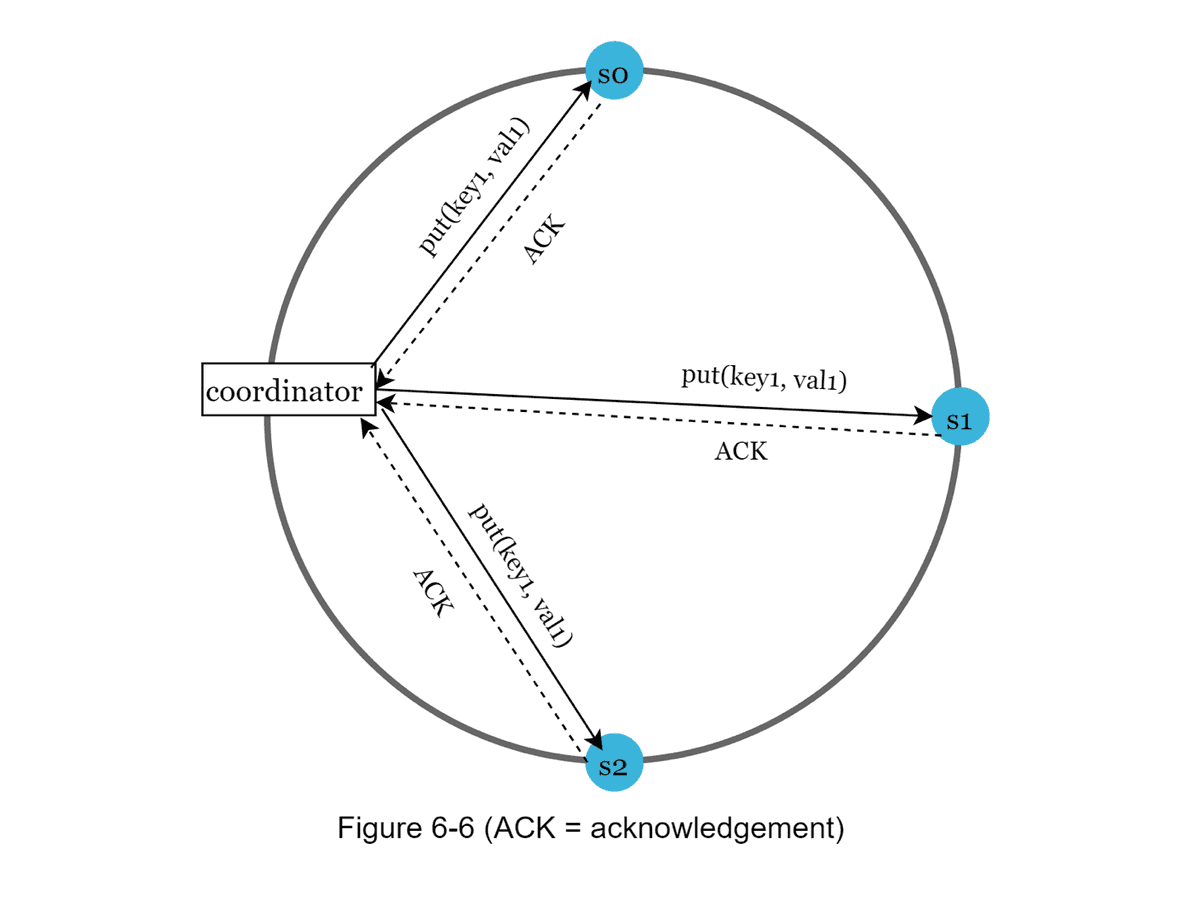
- Consistency Models: Strong, Weak, Eventual
- Inconsistency Resolution: "replication gives high availability but causes inconsistencies among replicas. Versioning and vector locks are used to solve inconsistency problems".
- Versioning: "Versioning means treating each data modification as a new immutable version of data."
- Vector Clock: resolve conflicts by the data client checking the version counter of the servers and repairing conflicts. This approach, however, adds complexity to the client because it needs to implement conflict resolution logic. Also, pairs in the [server: version] pairs could grow rapidly. This is not an ideal solution.
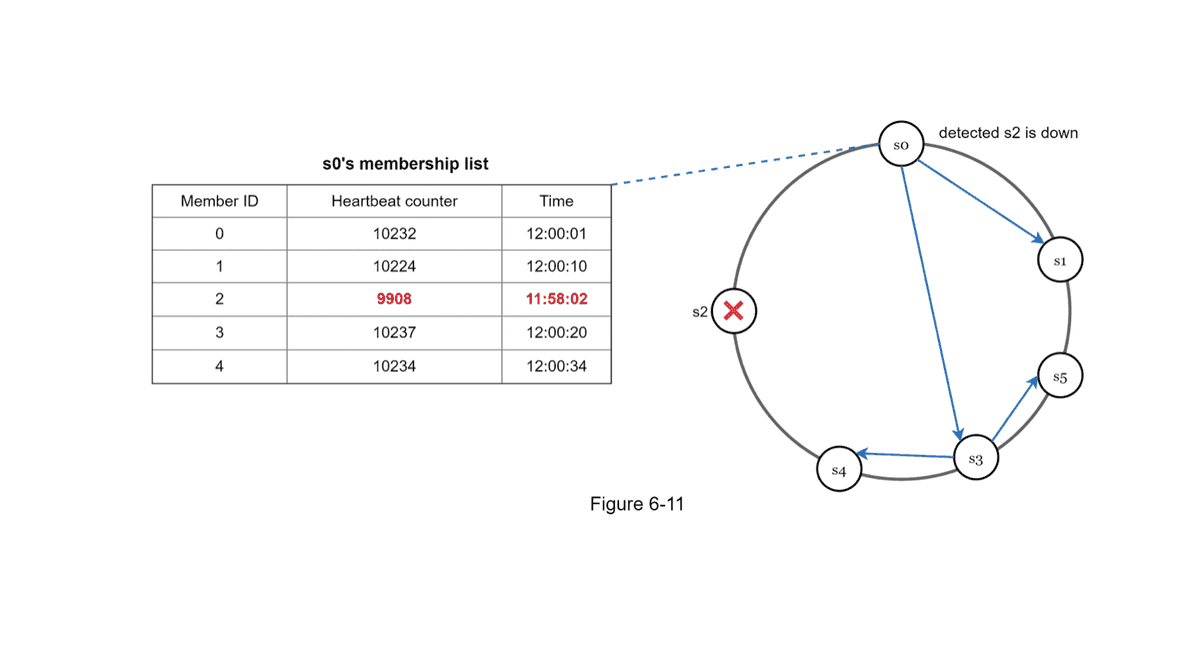
- Failure Detection
- Gossip Protocol
- Membership List
- Sloppy Quorum for handling temporary failures: prioritize reads and writes towards the verified healthy servers first
- Merkle Trees
- APIs: clients communicate with the KVS through simple APIs
get(key)andput(key, value)
Design a Unique ID Generator
- Multi-master Replication
- Universally Unique Identifier (UUID)
- Ticket Server
- Twitter Snowflake Approach
Issues
- Multi-master replication doesn't scale well with multiple data-centers or when servers are added or removed
- UUID uses a 128-bit alpha-numeric value. The requirements for size and value composition may not support this approach.
- Ticket Server approach introduces a centralized increment feature but this creates a single point of failure
Concepts
Twitter Snowflake Approach gives us a flexible and reliable ID Generation method that is independently scalable in a distributed architecture.
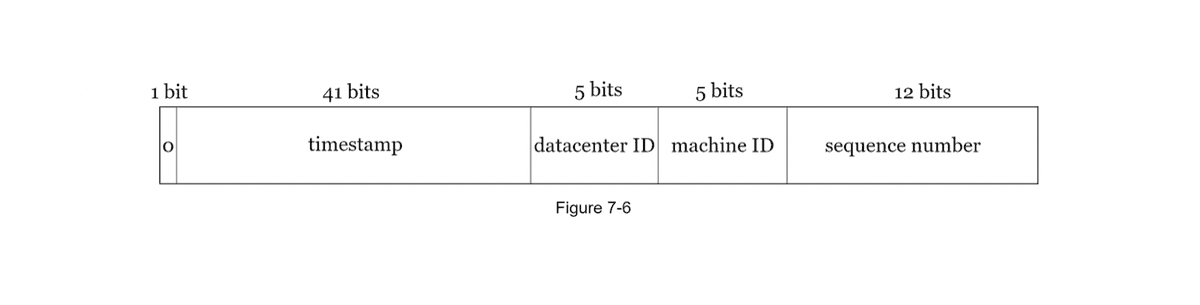
- Composite Sections
- Timestamp
- Data-center ID
- Machine ID
- Sequence Number
- Network Time Protocol
- Section Length Tuning
Design a URL Shortener
Issues
- Collision
- Hashing vs Base-62 conversion
Concepts
- REST-style API endpoints
- URL Redirects (301 permanent, 302 temporary)
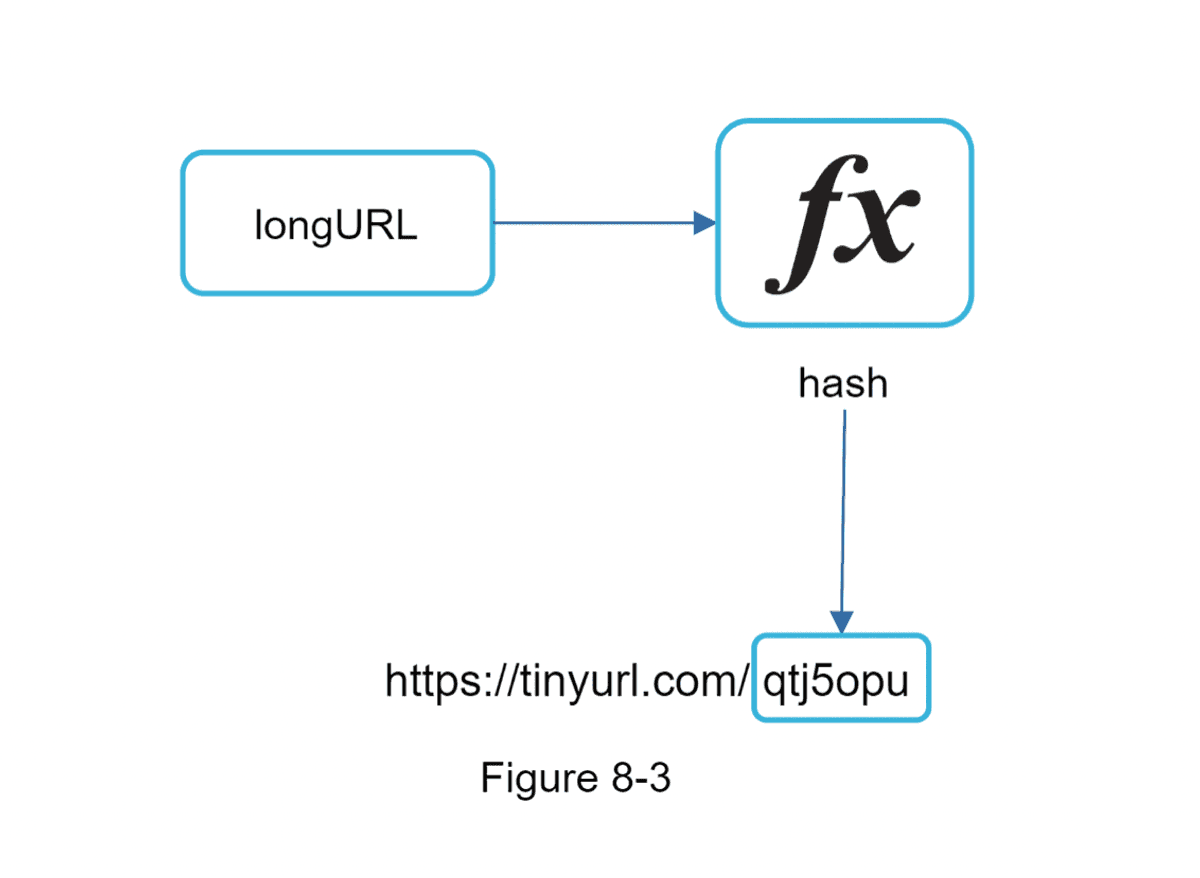
- Hash Function
- Returns a fixed length for a variable length LongURL
- Converts the LongURL to a ShortURL
- We can be (reasonably) sure will be unique
- Store the ShortURL and LongURL in a database table so that our interface can lookup the long from the short and vice versa
- Options for Hash Functions include CRC32, MD5, SHA-1
- Base-62
- Alternative to Hash Function
- Returns a variable length ShortURL
- Collision is not possible because ID is unique
Design a Web Crawler
Issues
- Robustness
- Politeness
- Extensibility: able to support new "Concept Types"
- Scalability: QPS, Peak QPS, Storage
Concepts
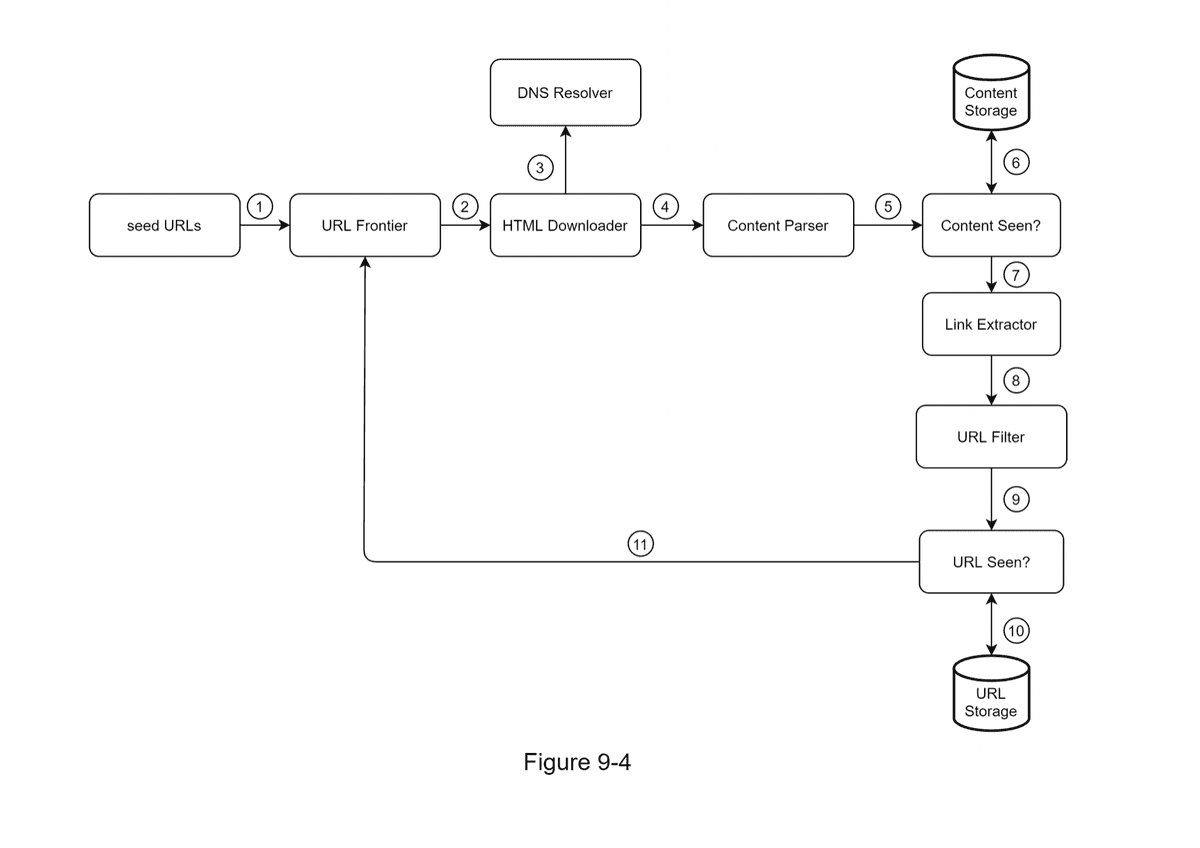
- Seed URLs / URL Frontier: split the crawl state into two (Downloaded, To-Be-Downloaded)
- HTML Downloader
- DNS Resolver
- Content Parser
- Content Seen Function: bloom filter or hash table to compare hash values of new and old web pages to determine if the content has been updated
- Content Storage: most stored on disk, popular can be stored in memory
- Link Extractor: extract from relative paths using prefix to separate namespaces and postfix to navigate trees
- URL Storage
- Directed Graph
- FIFO Queue
- Queue Router: ensures that each queue only contains URLs from the same host
- Mapping Table: maps each host to a queue
- Queue Selector: assigns worker threads to queues
- Problem Detection: Redundant Content, Spider Traps, Data Noise
Design a Notification System
Issues
- Different client device types
- Gathering Contact Info
- Maintaining a connection
Concepts
- Push Notification Services (e.g. Apple APNS for iOS, Firebase Cloud Message for Android, Twilio for SMS, Sendgrid or Mailchimp for eMail)
- Device Token
- Payload (JSON Dictionary)
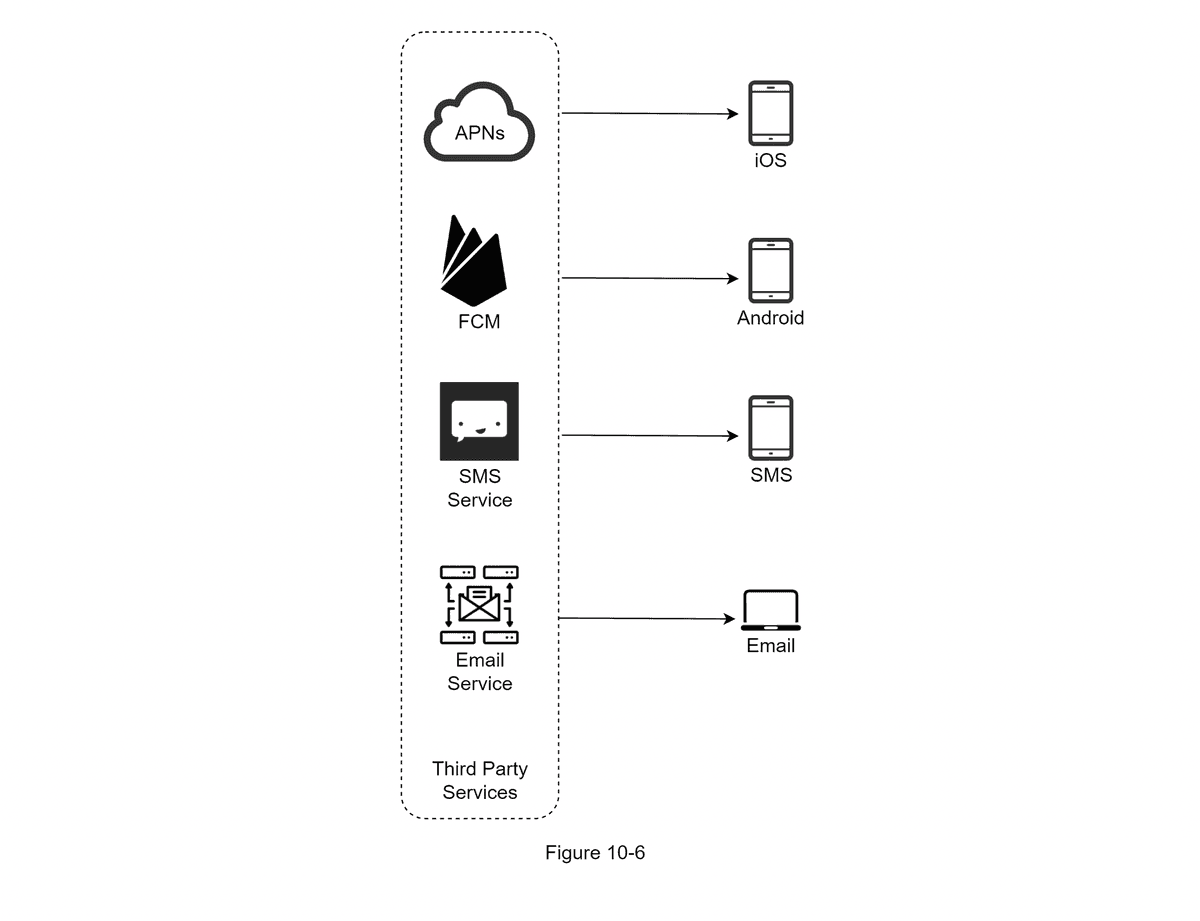
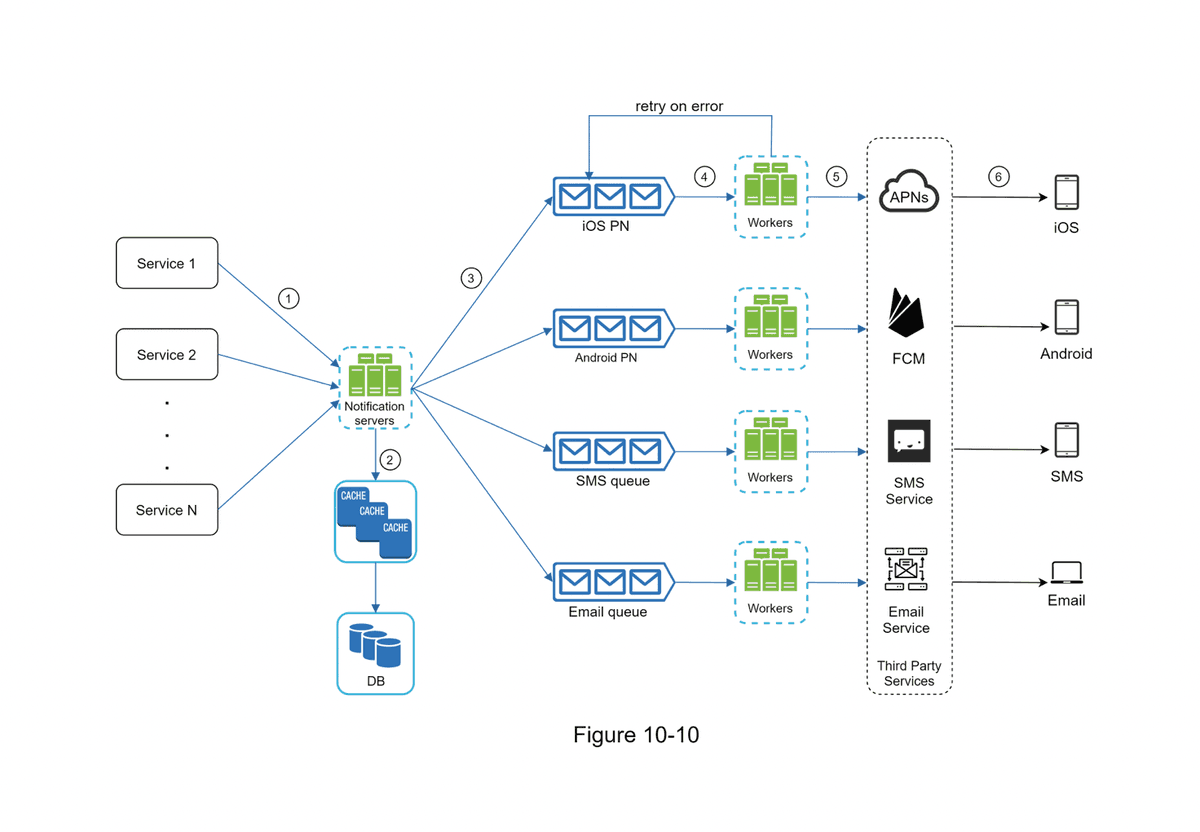
- Message Queues: remove dependencies between components, serving as buffers when high volumes of notifications need to be sent out. "Each notification type is assigneed with a distinct message queue so that an outage in one service will not affect others." (p. 180)
- Monitoring
- Event Tracking
- Retry Mechanism
Design a Newsfeed System
A newsfeed is a constantly updating list of stories in the middle of your home page.
The design is divided into two flows:
- Feed Publishing: enabling a user to publish a post
- Feed Building: enabling a user to view the Newsfeed aggregate of posts unique to that user
Issues
- Hotkey Problem: when a user has many friends, fetching the friend list and generating a newsfeed for all of them is expensive and slow
- Inactive Users: pre-computing new feeds for users that are rarely logged in wastes computing resources
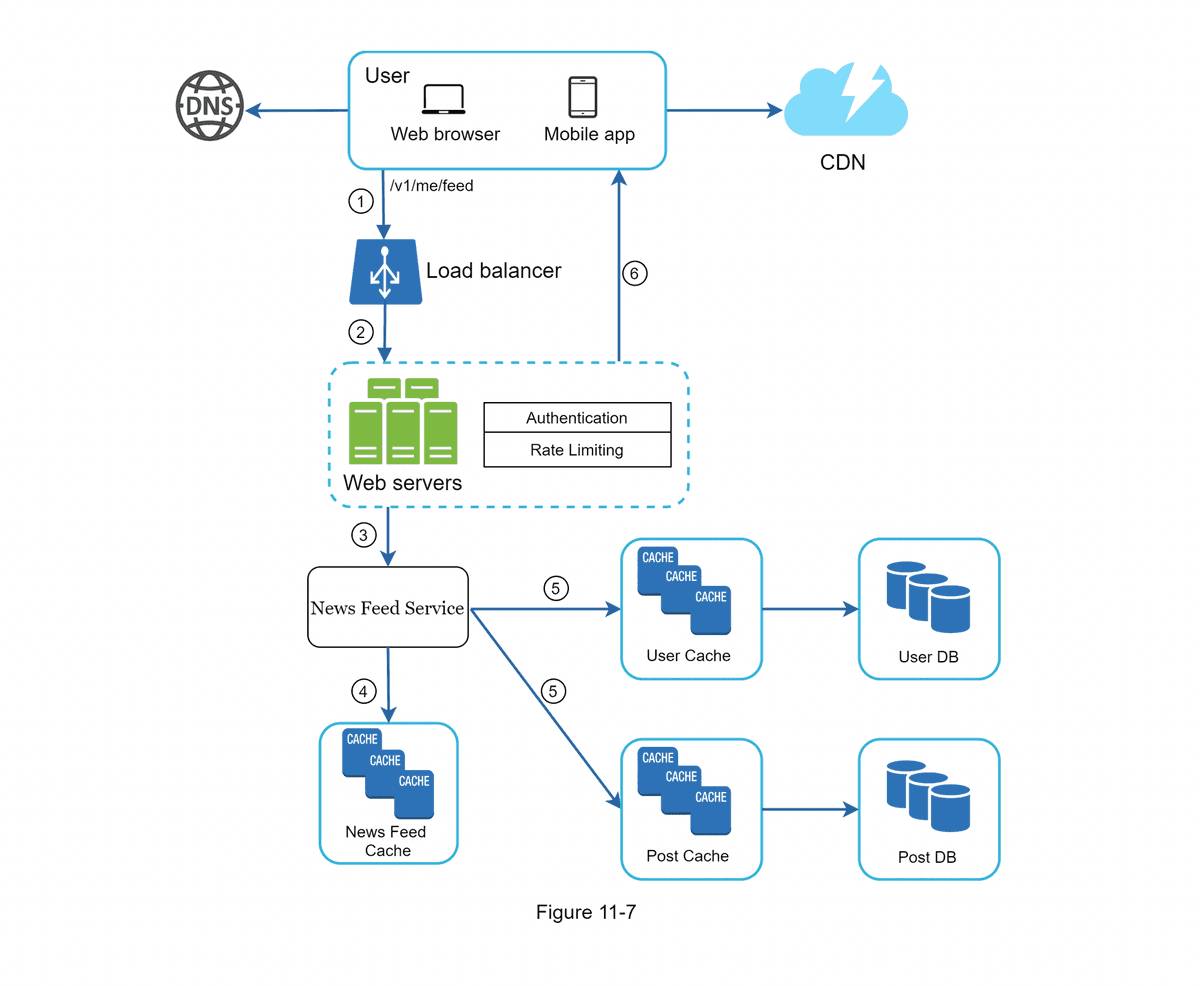
Concepts
- REST-style APIs (http POST, http GET)
- Fanout to Read: a newsfeed is generated during read time. This makes the user experience slow but saves on compute for inactive users
- Graph Database
- Authentication
- Rate Limiter
- Cache Architecture
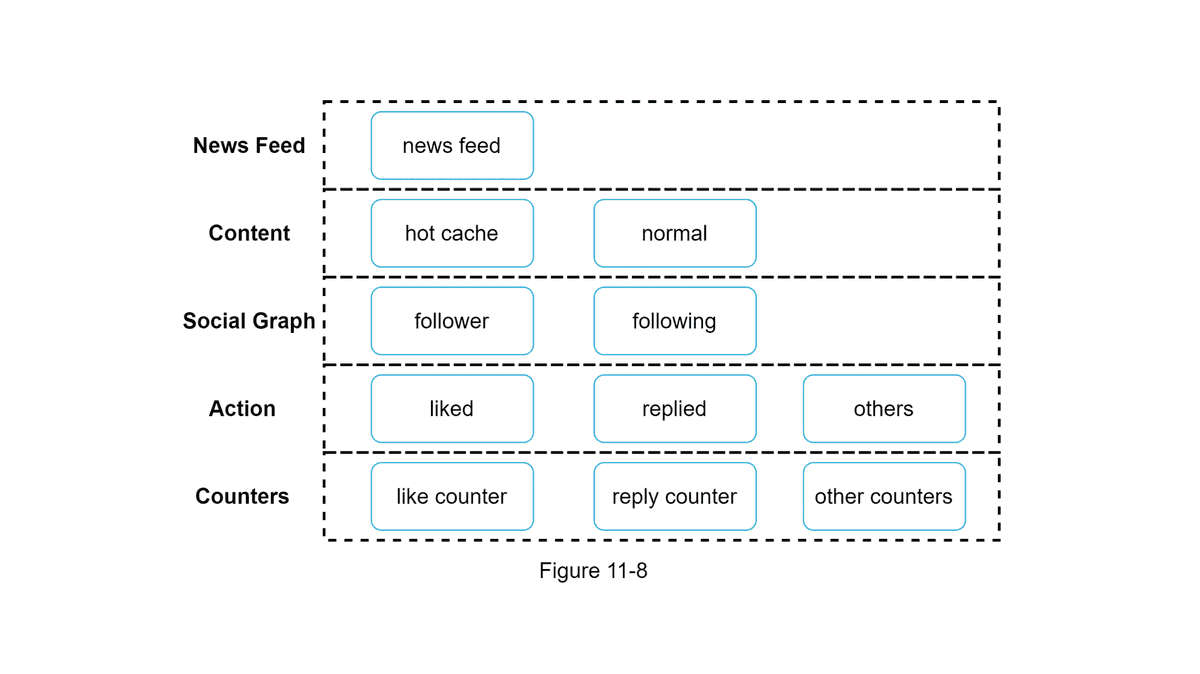
- Database Sharding
- Eventual Consistency Model
- Stateless Web Tier
- QPS Metric
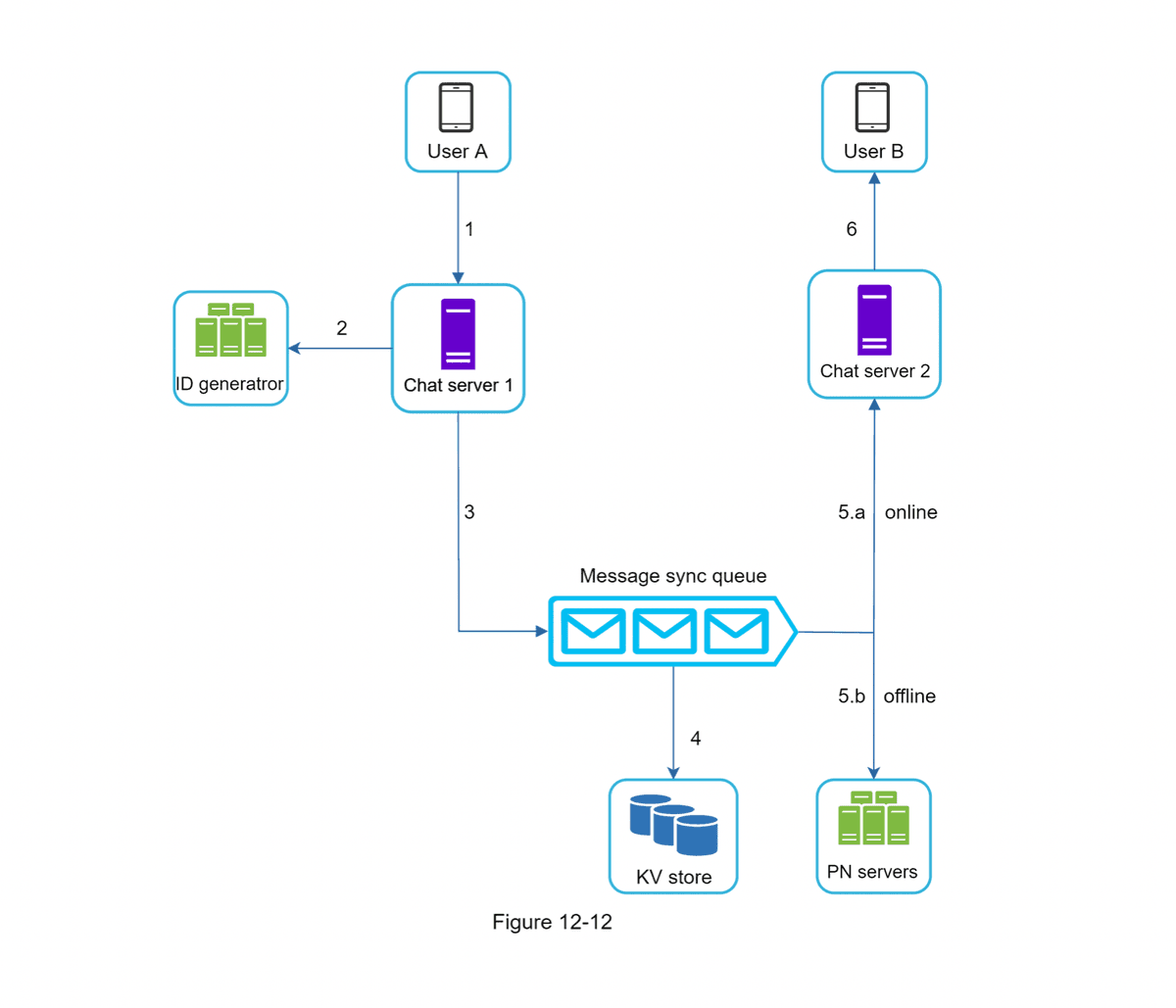
Design a Chat System
Issues
- Encryption
- Realtime Connectivity
- Message Storage
- Scalability
- Message Unique ID (use Snowflake or UUID or a local sequence number generator)
Concepts
- WebSockets: a bi-directional persistent connection that can be established by upgrading a HTTP/HTTPS connection
- Long Polling: client holds the connection open until there are new messages available or a timeout threshold has been reached
- Chat Servers: facilitate message sending/recieving
- Stateful Chat Service: maintains state because of the persistent connection
- Service Discovery: The role of service discovery is to "recommend the best chat server for a client based on the criteria like geographical location, server capacity, etc." Apache ZooKeeper is a popular open-source solution.
- Online Status Fanout: indicates to users when a friend's status has changed
- End-to-End Encryption: only sender and reciever can read message contents
- Error Handling (chat server error, message retry mechanism)