We — the software development community — need to overcome our emotional nature and find a better way of discussing and applying technology. A great way to discuss and describe technology is to use the pattern format, because it’s objective. When describing a technology in the pattern format, you must, for example, describe the drawbacks. (p. 20)

The Big Idea
Microservice Patterns by Chris Richardson makes the case for why Microservice architectural style is a good fit for some contexts, and discusses some of the important techniques and patterns that can be used to implement and maintain it.
The Microservices architecture style is a response to a set of important problems and trends: increased demands of business for change, limitations of commercial off the shelf products, advances in cloud infrastructure, and proliferation of niche cloud and opensource technologies. Products now trend towards large, distributed systems, ever-evolving, and made up on many disparate components, technologies, and teams.
The bad guy: "Monolithic Hell" is the place organizations all-too-often find themselves. When an application follows the monolithic architecture pattern, but the organization and software system has grown beyond its ability to cope, they have arrived. Dependencies between teams and systems make change difficult and side-effects are unpredictable.
The good guy: Microservices architectural style encapsulates functionality into loosely coupled, independently deployable services. This allows the application to be evolved in a way that reduces dependencies between teams and systems. In addition, its increases the system's flexibility which benefits team's ability to judge and make trade-offs, improving the fitness for the organization and business context.
✅ Loosely Coupled: All interaction with a service happens via its API, which encapsulates its implementation details.
✅ Independently Deployable: A well-designed service is one which is capable of being developed by a small team with minimal lead time and with minimal collaboration with other teams.
See microservices.io

The book does a good job of balancing theory and practical detail. The author avoids rabbit-holes of interesting but uncommon edge cases, instead focusing on the areas that matter, and gives examples that architects and engineers encounter in the real-world. This book is a practical guide for experienced practitioners and new entrants alike.
Below are summaries of a few of the sections I found most value.
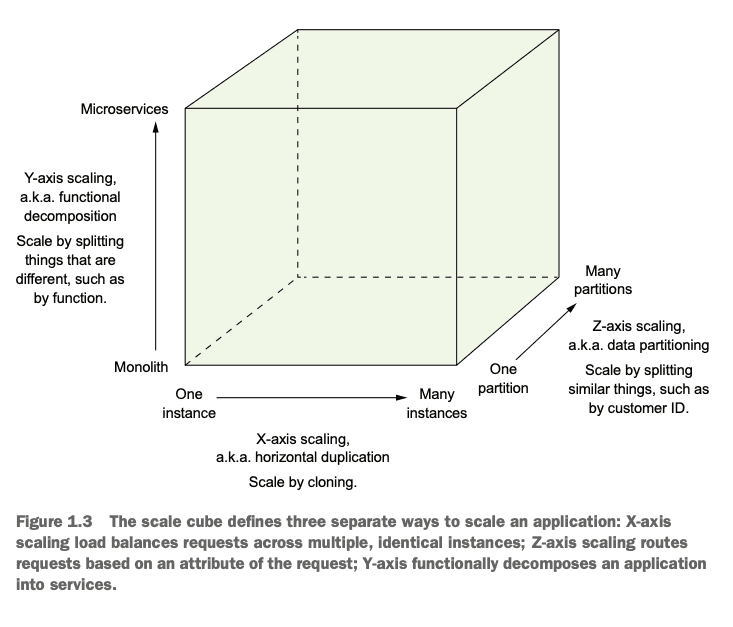
Scaling Microservices
Decoupling services from one another opens up a variety of scaling strategies that can be summarized in the 3 Dimensions of Scaling:


Decomposition Strategies
To develop a microservice architecture for your application, you need to identify the services and determine how they collaborate.
The author introduces Domain Driven Design early as a way of decomposing a system down to smaller parts. As discussed above, the problem with the traditional monolithic architecture is that it makes the unlikely assumption that the layered architecture will sufficiently explain the purpose of component parts relative to one another, and the relationships between them. This is implausible. It leads to bloat in various components, and fails to help architects and programmers to reason about components that may exist externally.
The Monolithic architectural style is in some ways a holistic Technology-First paradigm. Domain Driven Design replaces this with a Business-first architectural style. This addresses the nature of modern technology systems to change frequently. It also addresses problem that a technology-first view is necessarily exclusive - allowing only some of the people involved in building and maintaining the system to understand it.
In contrast, business problems remain relatively constant. In addition, DDD helps teams to define business problems more narrowly into domains and subdomains, enabling architects to align business and engineering into smaller systems. And if teams are focused on the business problems, they're more likely to build valuable software.
The author brings into focus the architectural benefits of encapsulating relevant business logic to its business domain.
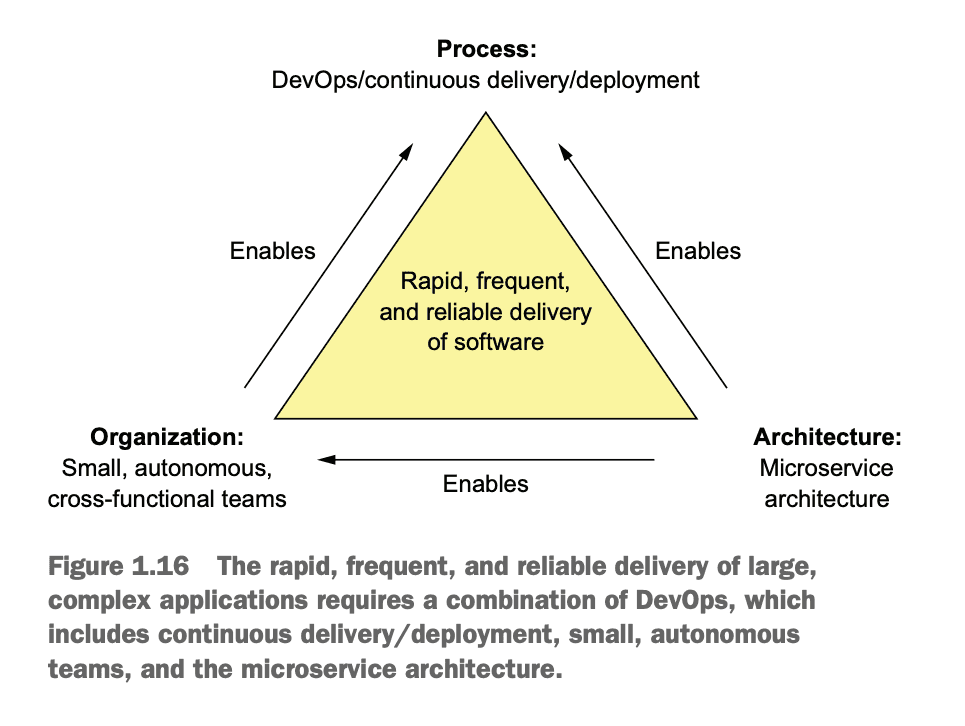
The author presents the Microservices architectural style as usually the best choice for large, complex applications because of this virtuous loop between architecture, organization, and process. This is in deference to the "Conway's Law", which predicts architectures will naturally evolve to reflect the organizations that create them. The "Reverse Conway's Maneuver" uses this tendency by devision an architecture that aligns to the business structure that exists, and the organizational structure that we want. Technology will naturally evolve to encapsulate dependencies within itself. Aligning organizational design to business domain naturally leads to a system that encapsulates its dependencies. That means faster and more predictable delivery.
3 Step Process for Decomposition
- Identify the System Operations
- Identify Services
- Define Service APIs and Collaborations
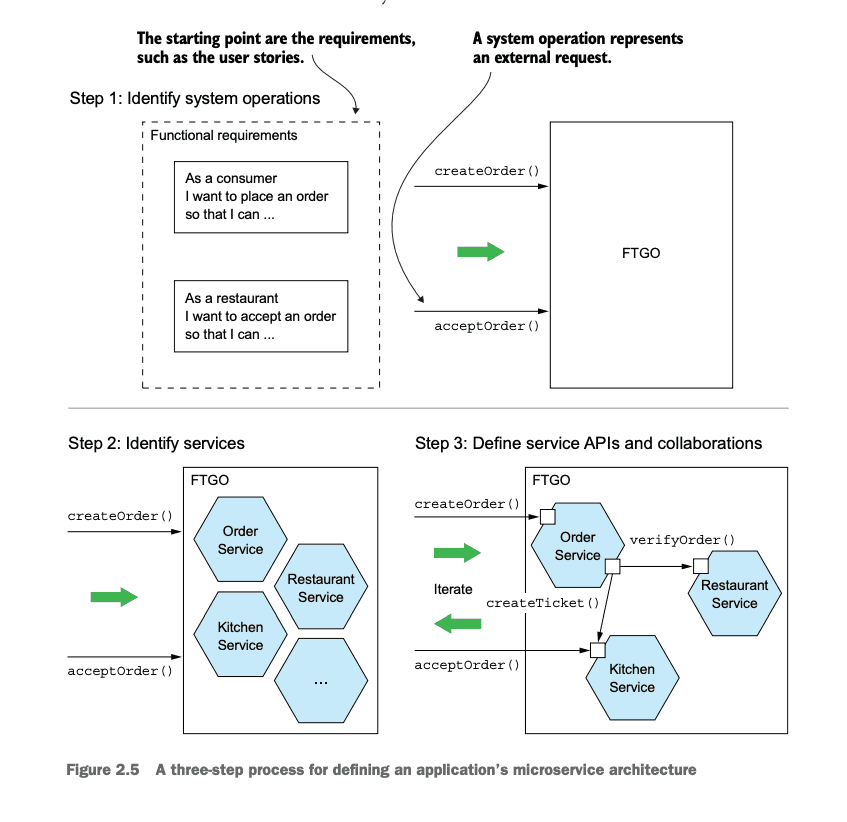
Identify the System Operations
Identify System Operations starts with the process of establishing the high-level domain model.
Despite being a drastic simplification, a high-level domain model is useful at this stage because it defines the vocabulary for describing the behavior of the system operations. (p. 46)
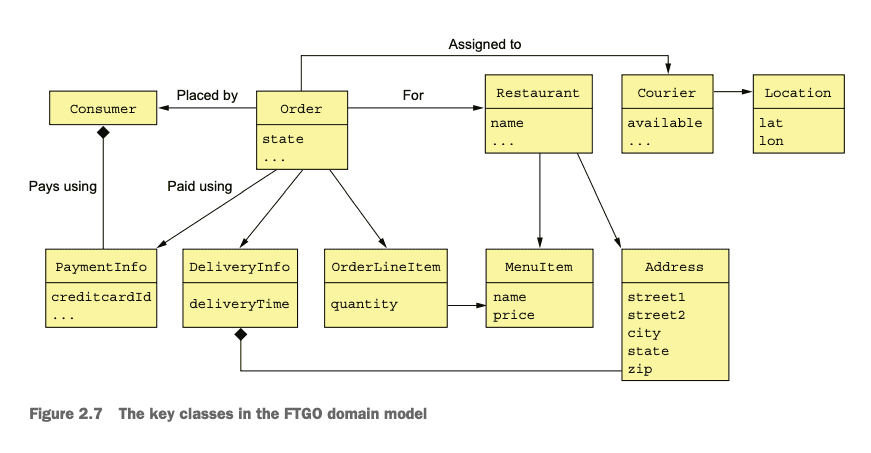
Questions
- What are the responsibilities of each class?
- What are the System Operations (Commands / Queries)?
- What user scenarios help us animate the System Operations?
Identify Services by Business Capabilities
Decompose by Business Capability
An organization’s business capabilities capture what an organization’s business is. They’re generally stable, as opposed to how an organization conducts its business, which changes over time, sometimes dramatically. That’s especially true today, with the rapidly growing use of technology to automate many business processes.
See [microservices.io](http://microservices.io/ patterns/decomposition/decompose-by-business-capability.html)
Map Business Capabilities to Services
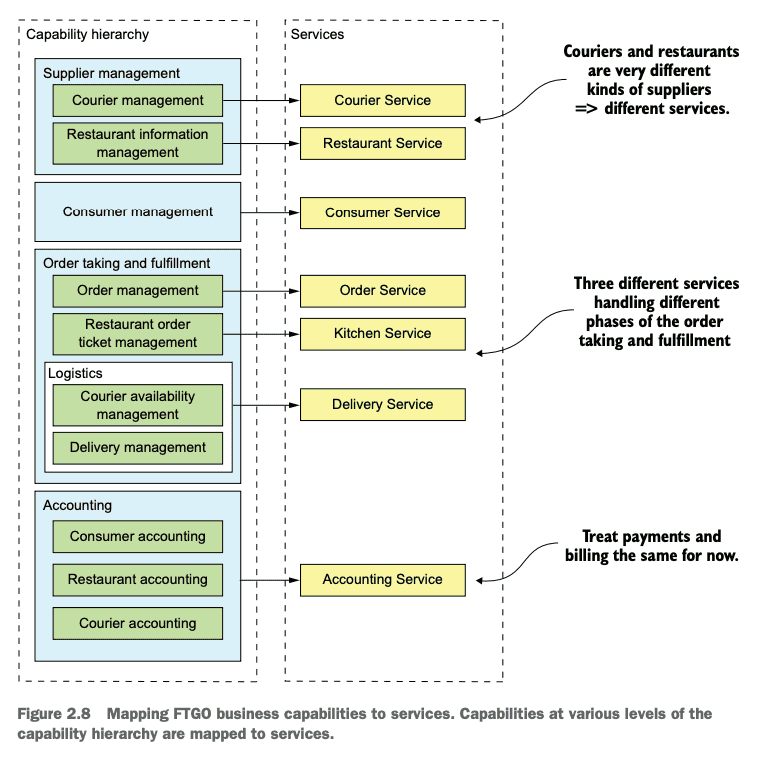
A key benefit of organizing services around capabilities is that because they’re stable, the resulting architecture will also be relatively stable. The individual components of the architecture may evolve as the how aspect of the business changes, but the architecture remains unchanged.
Identifying Services by Subdomain with DDD
At the level of the enterprise, DDD takes a much different approach than the Business Capabilities Model. It allows for variation within the business to redefine a given entity in its own terms.
Subdomains are identified using the same approach as identifying business capabilities: analyze the business and identify the different areas of expertise. The end result is very likely to be subdomains that are similar to the business capabilities.
DDD calls the scope of a domain model a bounded context.
Decomposition Guidelines
Two principles from OOD that are especially applicable to defining a Microservice architecture.
- Single Responsibility Principle: "A class should have only one reason to change." - Robert C. Martin. If a class has multiple responsibilities that change independently, the class won’t be stable.
- Common Closure Principle: If two classes change in lockstep because of the same underlying reason, then they belong in the same package.
Obstacles to Decomposing an Application into Services
(This section I found extremely helpful and concise so this is mostly excerpts from p. 57-59)
- Network latency: Network latency is an ever-present concern in a distributed system. You might discover that a particular decomposition into services results in a large number of round-trips between two services. Sometimes, you can reduce the latency to an acceptable amount by implementing a batch API for fetching multiple objects in a single round trip. But in other situations, the solution is to combine services, replacing expensive IPC with language-level method or function calls.
- Reduced availability due to synchronous communication: distributed synchronous interservice communication compromises availability via the CAP theorem. Asynchronous communication is often necessary and introduces some other challenges.
- Maintaining data consistency across services: The traditional solution is to use a two-phase, commit-based, distributed transaction management mechanism. But this is not a good choice for modern applications, and you must use a very different approach to transaction management, a saga. A saga is a sequence of local transactions that are coordinated using messaging. Sagas are more complex than traditional ACID transactions but they work well in many situations. One limitation of sagas is that they are eventually consistent. If you need to update some data atomically, then it must reside within a single service, which can be an obstacle to decomposition.
- Obtaining a consistent view of the data: in a microservice architecture, even though each service’s database is consistent, you can’t obtain a globally consistent view of the data
- God classes preventing decomposition: bloated classes that are used throughout an application
Communication Patterns
Communication patterns are organized into 5 groups:
- communications style
- discovery
- reliability
- transaction messaging
- API patterns
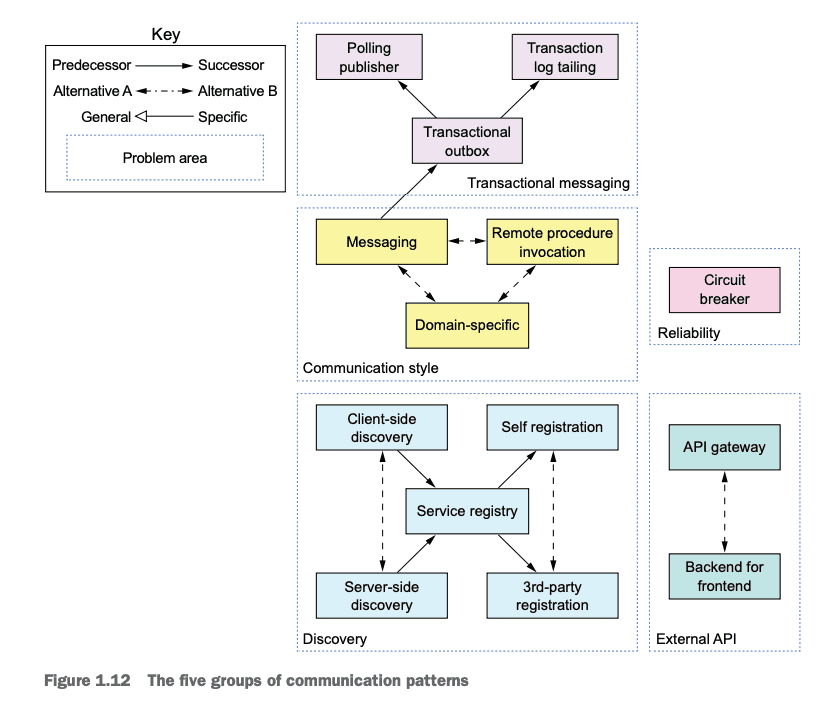
Each group is covered in depth in the book. Particularly helpful is the authors discussion of API patterns in Chapter 8.
API Communication Patterns
The challenge of designing APIs that support a diverse set of clients
The Microservice architecture can introduce a challenge where clients are required to make many requests over the internet which is slow and can add a lot of complexity to the client code.
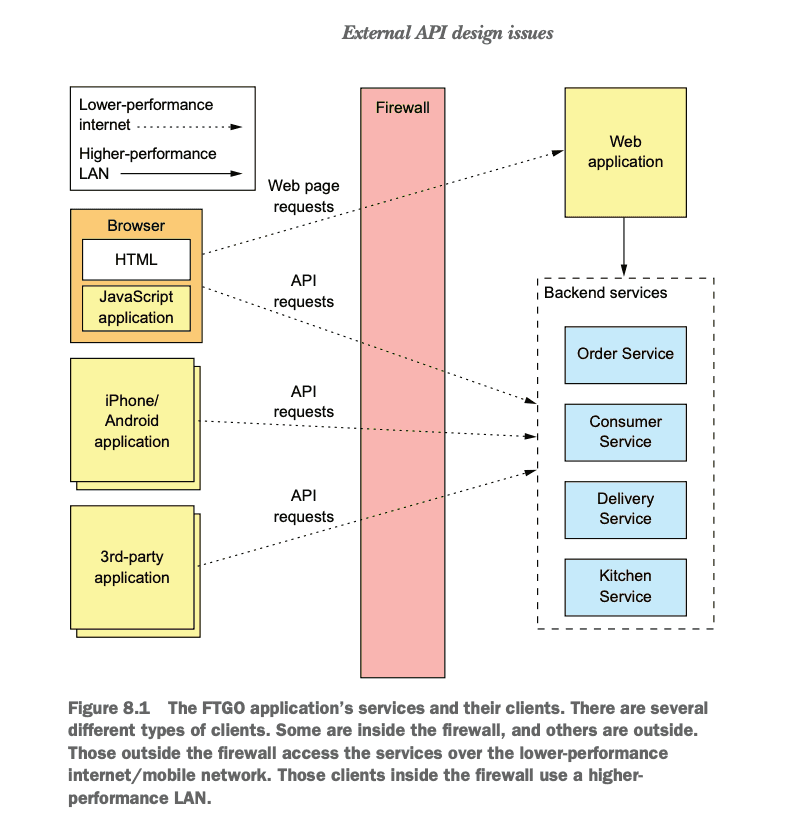
The latency introduced by making requests over the internet can result in a poor end user experience. The lack of encapsulation of the backend services introduces complexity into the client and a tighter coupling. Frontend developers may often be required to change their code in lockstep with the backend.
In addition, it risks the idiosyncrasies of the service communication mechanisms to be absorbed by the clients such as client-unfriendly IPC such as gRPC and AMQP. Ideally, communication over the internet should be limited to client friendly IPC like REST.
Applying API gateway and Backends for frontends patterns
An API gateway is a service that’s the entry point into the application from the outside world. It’s responsible for request routing, API composition, and other functions, such as authentication. (p. 259)
Microservices.io - API Gateway Pattern
The API Gateway pattern enables encapsulation of backend service complexity. In these cases an API gateway performs API composition, allowing clients to efficiently retrieve data using a single API request which fans out to other services over the low-latency network. Implemented properly, this helps prevent tight coupling between the client and services.
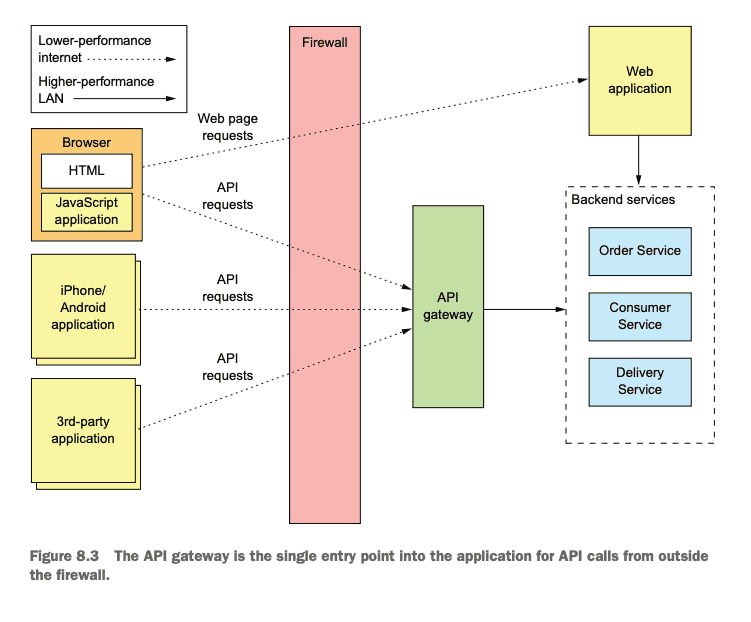
In addition, the API gateway is often responsible for protocol translation. It may provide a RESTful endpoint for external consumers even though it communicates with services that use a variety of protocols, REST, gRPC, and AMQP.
There are tradeoffs when introducing this pattern including adding a potential single point of failure. This risk can be mitigated by leveraging a high-availability, high-reliability API gateway such as AWS API Gateway.
In addition the API Gateway can be a way to improve service to service communication on the backend. However, this can sometimes lead to the "Distributed Monolith" anti-pattern. Watch for chattyness between services as a sign of tight coupling and improperly established service boundaries. This adds latency, complexity, and network bandwidth congestion.
API Gateway can be an opportunity to locate general functions close to the client. Common Edge Functions include:
- Authentication: Verifying the identity of the client making the request
- Authorization: Verifying that the client is authorized to perform that particular operation
- Rate limiting: Limiting how many requests per second from either a specific client and/or from all clients
- Caching: Cache responses to reduce the number of requests made to the services
- Metrics collection: Collect metrics on API usage for billing analytics purposes
- Request logging: Log requests
Alternatively, these Edge Functions can be leveraged as standalone services. The benefit is that is of a separation of concerns :the API Gateway responsible primarily for routing and translation while a separate Edge Function could "Gateway agnostic", developed, maintained, and deployed independently. The drawback of this practice is that it increases network latency because of the extra hop, and adds complexity.
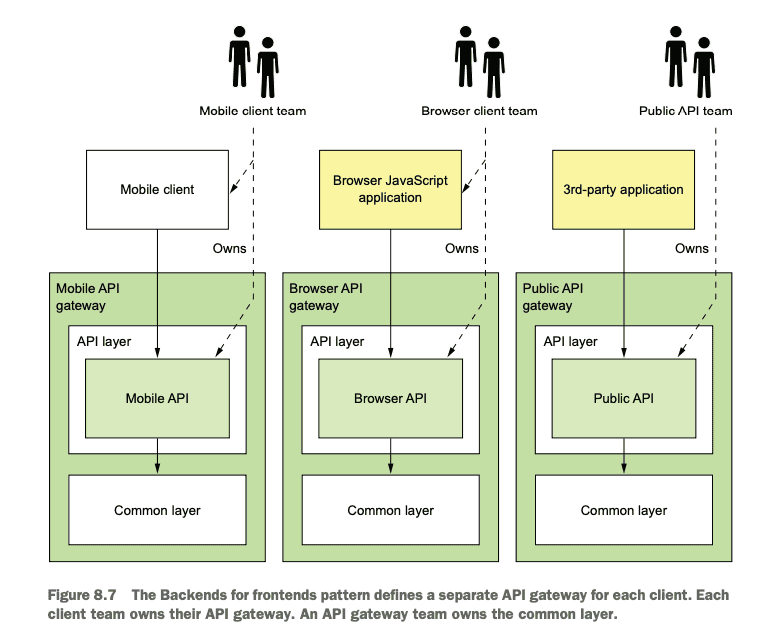
One issue the author raises is the question of ownership. A common anti-pattern is that the API Gateway becomes a bottleneck to fast flow. In these cases, usually a client team would be dependent on a team owning the API Gateway. This added queue meant that the speed of change would be highly dependent upon this central team.
The Backends for Frontends (BFF) model introduces a two sided API Gateway. One side responsible for internal communication and Edge Functions, the other side owned by the Client team which could customize its own stand-alone API gateway, specific to its client requirements.
Designing and implementing an API gateway
Design Challenges include:
- Performance and scalability
- Writing maintainable code by using reactive programming abstractions
- Handling partial failure
- Being a good citizen in the application’s architecture
Performance and scalability leads to a number of tradeoffs including synchronicity, blocking I/O, and "callback hell".
Using reactive programming to simplify API composition
Reactive Programming abstractions become a key feature of the API Gateway Pattern. As mentioned earlier, API composition consists of invoking multiple backend services. Some backend service requests may depend entirely on the client request’s parameters. Others might depend on the results of other service requests. In these cases writing API composition code using the traditional asynchronous callback approach quickly leads you to callback hell. "A much better approach is to write API composition code in a declarative style using a reactive approach." (p. 270)
Implementing an API gateway - AWS API Gateway
An AWS API gateway API is a set of REST resources, each of which supports one or more HTTP methods. You configure the API gateway to route each (Method, Resource) to a backend service. A backend service is either an AWS Lambda Function, [...] an application defined HTTP service, or an AWS service. If necessary, you can configure the API gateway to transform request and response using a template-based mechanism. The AWS API gateway can also authenticate requests.
The AWS API Gateway fulfills some of the requirements for an API gateway including auto-scaling, but it doesn’t support API composition, so you’d need to implement API composition in the backend services.
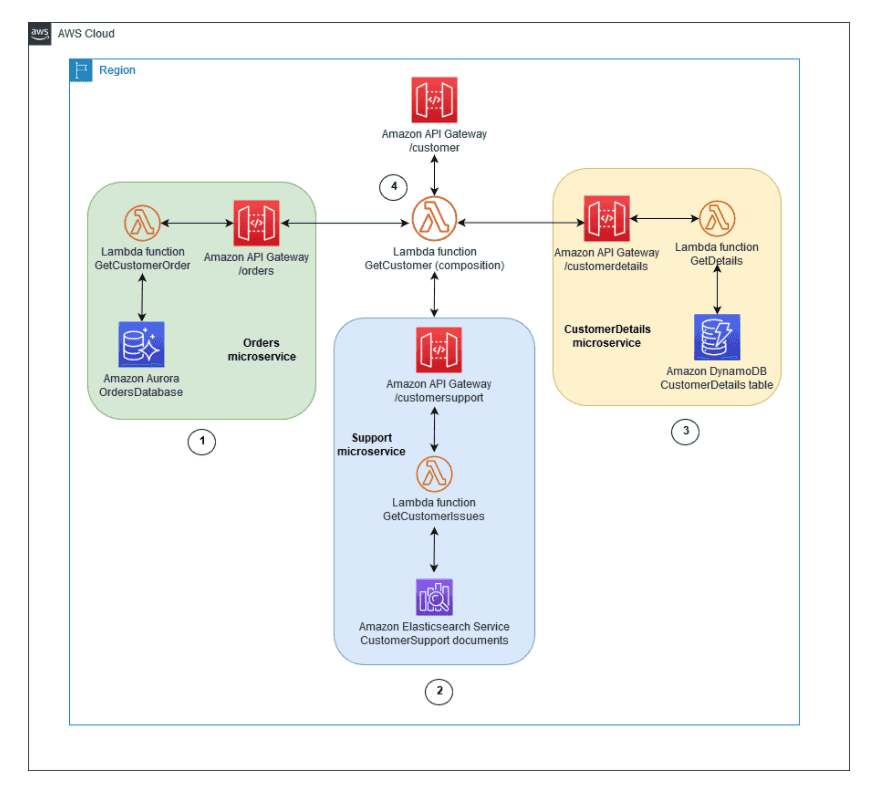
The API composition pattern offers the simplest way to gather data from multiple microservices. However, there are the following disadvantages to using the API composition pattern:
- It might not be suitable for complex queries and large datasets that require in-memory joins.
- Your overall system becomes less available if you increase the number of microservices connected to the API composer.
- Increased database requests create more network traffic, which increases your operational costs.
The AWS API gateway also only supports HTTP(S) with a heavy emphasis on JSON. It only supports the server-side discovery pattern. [...] Despite these limitations, the AWS API Gateway is a good option in many cases. (p. 271)
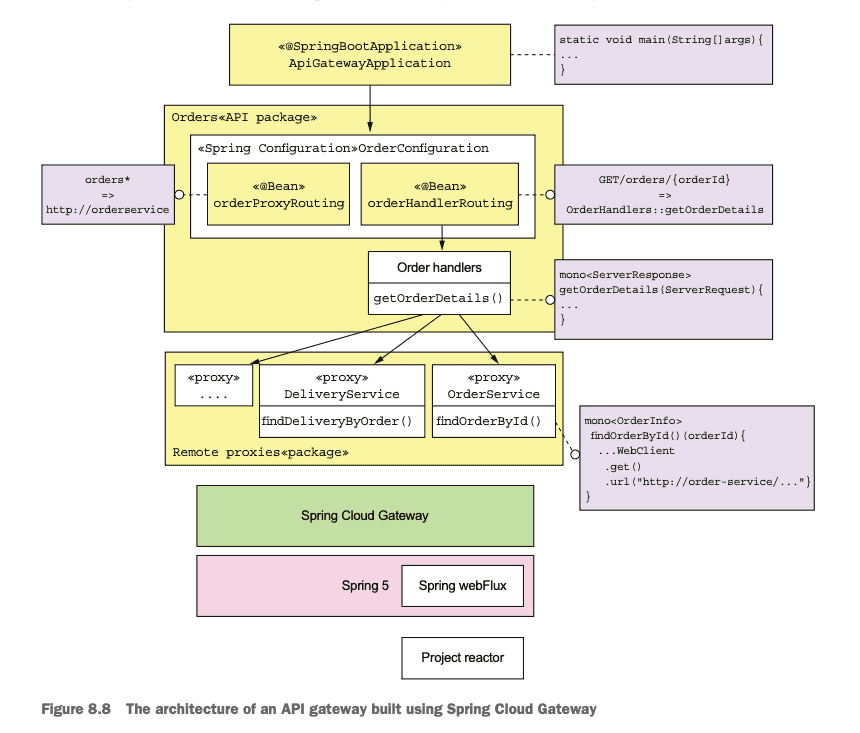
Implementing an API gateway - Spring Cloud Gateway
Spring Cloud Gateway provides a simple yet comprehensive way to do the following:
- Route requests to backend services.
- Implement request handlers that perform API composition.
- Handle edge functions such as authentication.
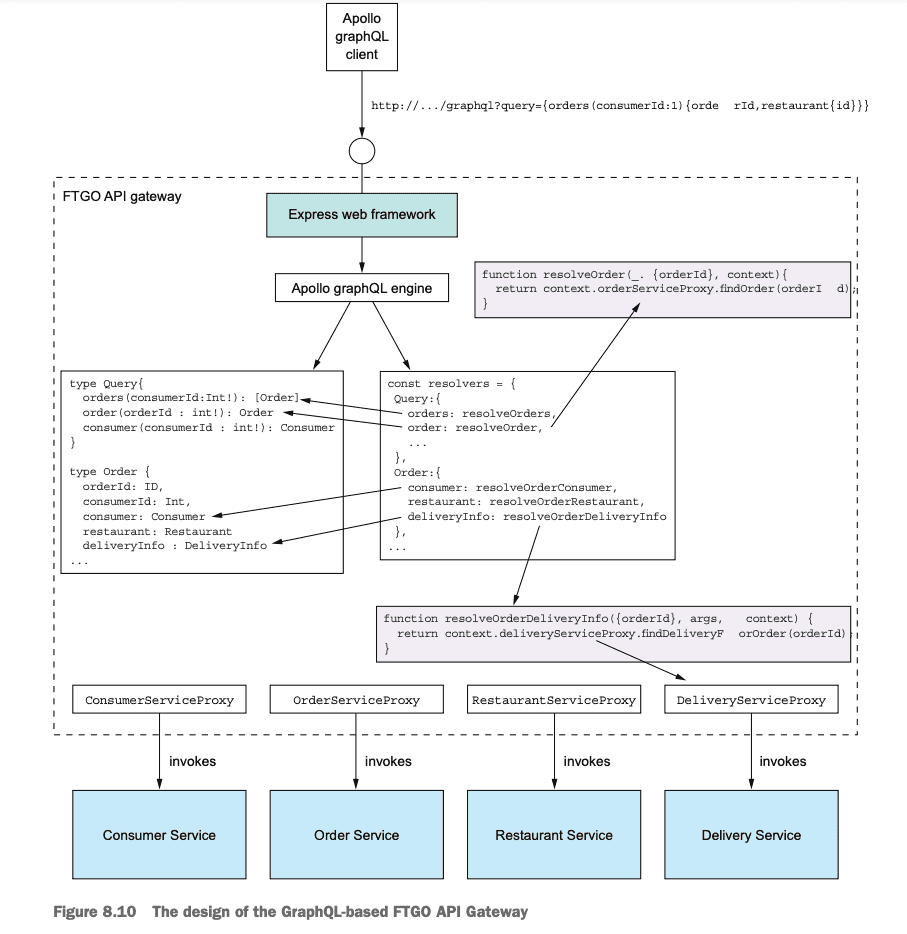
Implementing an API gateway - GraphQL
Different clients need different data. One of the benefits of GraphQL is its ability for data discovery and to write custom queries to retrieve data. It is especially intuitive for developers and enables Client teams to discover and retrieve data extremely quickly and with maximum flexibility, abstracting away all the backend complexity.
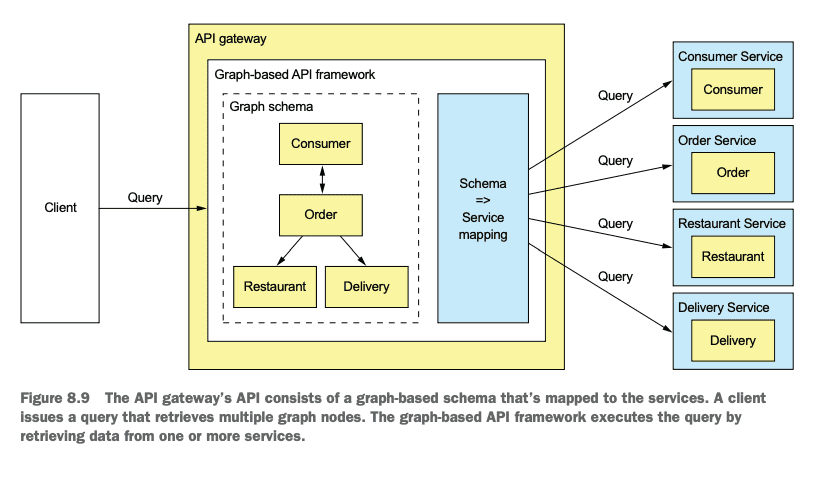
GraphQL, that’s designed to support efficient data fetching. The key idea with graph-based API frameworks is that, as figure 8.9 shows, the server’s API consists of a graph-based schema. The graph-based schema defines a set of nodes (types), which have properties (fields) and relationships with other nodes. The client retrieves data by executing a query that specifies the required data in terms of the graph’s nodes and their properties and relationships.
The two most popular graph-based API technologies are GraphQL (http://graphql.org) and Netflix Falcor (http://netflix.github.io/falcor/).
The author offers an example of an API Gateway developed for the FTGO app discussed throughout the book.